







































Quel est l’élément essentiel qui sépare un texte écrit par un être humain d’un texte généré par un algorithme, lorsque ledit algorithme utilise comme entrée une base de données massive de textes écrits par des humains ? Cela semble être le combat fondamental auquel la société est actuellement confrontée, alors que se profile la perspective d’un avenir dans lequel les étudiants pourront faire auto-générer des essais à partir de grands modèles de langage (LLM) et les auteurs pourront produire des livres par douzaines sans faire plus que demander audit algorithme de l’écrire pour eux, en utilisant rien de plus qu’une requête contenant le contenu souhaité comme entrées humaines.
En raison de l’immense quantité de texte généré par l’homme dans un tel LLM, il existe un chevauchement certain entre le texte généré par la machine et la prose moyenne d’un auteur humain. Les méthodes statistiques de détection des premiers sont également de plus en plus paralysées par les développeurs humains et autres travailleurs humains derrière ces algorithmes de génération de texte, créant juste assez d’aléatoire de type humain dans le vocabulaire prédictif de l’algorithme pour convaincre le lecteur occasionnel qu’il a été écrit par un autre humain. .
Peut-être que le meilleur moyen de détecter le texte généré par une machine réside peut-être dans cette qualité dont ces algorithmes sont souvent annoncés, mais dont ils sont en réalité complètement dépourvus : l’intelligence.
Statistiquement humain

Pendant très longtemps, les textes générés par des machines étaient facilement identifiables par un observateur occasionnel dans la mesure où ils employaient un style d’écriture plutôt particulier. Non seulement leur formulation serait extrêmement générique et se répéterait avec de nombreuses répétitions, mais leur vocabulaire utilisé serait également très prévisible, n’utilisant qu’un petit sous-ensemble de mots (populaires) plutôt qu’un vocabulaire plus diversifié et imprévisible.
Cependant, au fil du temps, l’évidence des textes générés par des machines est devenue moins évidente, à tel point qu’il y a pratiquement une chance sur deux de faire la bonne supposition, comme l’indiquent des études récentes. Par exemple Elizabeth Clark et coll. les LLM GPT-2 et GPT-3 utilisés dans l’étude n’ont convaincu les lecteurs humains que dans environ la moitié des cas que le texte qu’ils lisaient avait été écrit par un humain plutôt que généré par une machine.
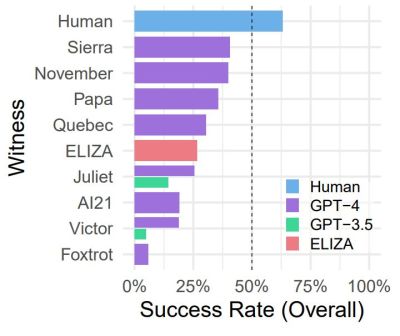
un sous-ensemble de témoins. (Crédit : Cameron Jones et al., 2023)
Il existe ensuite une série d’expériences liées au test de Turing, comme celle menée par Daniel Jannai et ses collègues, dans laquelle les participants humains n’ont deviné l’identité de leur interlocuteur anonyme que dans 68 % des cas. Une autre expérience de Cameron Jones et de ses collègues s’est concentrée principalement sur le LLM GPT-4 moderne, en le comparant à d’autres LLM et aux premiers chatbots comme le célèbre ELIZA des années 1960.
Cette dernière expérience est peut-être la plus fascinante, car bien qu’elle ait utilisé un test public en ligne, elle n’a pas opposé un seul LLM à des interrogateurs humains, mais plutôt un large éventail d’approches technologiques différentes, chacune visant à faire croire à un humain qu’il est parler avec un autre être humain intelligent. Comme le montrent les résultats des tests (photo), ELIZA s’en sort plutôt bien, surpassant largement le GPT-3.5 LLM et donnant au GPT-4 une chance pour son argent. Le nœud du problème – qui est également abordé dans l’article de Cameron Jones – semble donc être la manière dont un lecteur humain juge l’intelligence derrière ce qu’il lit, avant d’être sûr de parler avec un véritable être humain.
Étant donné que même les humains réels participant à cette expérience ont été jugés dans de nombreux cas comme n’étant pas suffisamment «humains», cela soulève la question non seulement de ce qui distingue un humain d’un algorithme, mais aussi de la mesure dans laquelle nous projetons nos propres préjugés et sentiments. sur le sujet d’une conversation ou sur l’auteur présumé d’un texte.
Vouloir Croire
Qu’est-ce que l’intelligence ? Plus succinctement, il s’agit de la capacité de raisonner et de réfléchir, ainsi que d’apprendre et d’avoir conscience non seulement du présent, mais aussi du passé et du futur. Pourtant, aussi simple que cela puisse paraître, nous, les humains, avons du mal à l’appliquer de manière rationnelle à tout, des animaux de compagnie aux bébés nés avec une anencéphalie, où l’instinct et les actions inconscientes sont confondus avec l’intelligence et le raisonnement. Tout comme nos cerveaux seront heureux de voir des motifs et des formes là où ils n’existent pas, ces mêmes cerveaux accepteront quelque chose comme créé par l’homme lorsqu’il correspond à nos notions préconçues.
Les gens citent souvent les résultats de ChatGPT – qui est généralement soutenu par le GPT-4 LLM – comme un exemple d’« intelligence artificielle », mais ce qui n’est pas mentionné ici, c’est l’énorme quantité de travail humain impliquée pour maintenir cette apparence. Une enquête de 2023 par Revue new-yorkaise et Le bord a découvert le grand nombre de soi-disant annotateurs : des personnes chargées d’identifier, de catégoriser et d’annoter tout, des réponses des clients aux fragments de texte en passant par des quantités infinies d’images, selon que le LLM et son interface sont utilisés ou non pour le support client, un chatbot comme ChatGPT ou pour trouver des données d’image correspondantes à fusionner pour s’adapter aux paramètres demandés.
Cela nous amène à la conclusion la plus évidente à propos des LLM et similaires : ils ont besoin de ces travailleurs humains pour fonctionner, car malgré les nobles affirmations sur les « réseaux de neurones » et les « RNN auto-apprenants », les modèles de langage ne possèdent pas de compétences cognitives, ou comme Konstantine Arkoudas le met dans son article intitulé GPT-4 ne peut pas raisonner: « [..] malgré quelques éclairs occasionnels de génie analytique, GPT-4 est actuellement totalement incapable de raisonner.
Dans son article, Arkoudas utilise vingt et un problèmes de raisonnement divers qui ne font partie d’aucun corpus sur lequel GPT-4 aurait pu être formé pour poser des questions à la fois très basiques et plus avancées à une instance ChatGPT, avec des résultats allant de comiquement incorrects à incroyablement faux, car ChatGPT ne parvient même pas à vérifier qu’une personne décédée à 23 heures était logiquement toujours en vie à midi plus tôt dans la journée.
Enfin, il est difficile d’oublier les cas où un professionnel du droit tente de convaincre ChatGPT de faire son travail à sa place et est logiquement radié du barreau en raison des résultats inoubliables et terribles.
Poser des questions
Pouvons-nous détecter de manière fiable les textes générés par LLM ? Dans un article de mars 2023 rédigé par Vinu Sankar Sadasivan et ses collègues, ils constatent qu’aucune méthode fiable n’existe, car la simple méthode de paraphrase suffit à vaincre même le filigrane. En fin de compte, cela rendrait vaine toute tentative de classer de manière fiable un texte donné comme étant généré par un humain ou une machine de manière automatisée, le tirage à pile ou face étant probablement aussi précis. Malgré cela, il existe un moyen de détecter de manière fiable les textes générés, mais cela nécessite l’intelligence humaine.
L’auteur et développeur principal de Curl – Daniel Stenberg – a récemment publié un article succinctement intitulé Le I en LLM signifie intelligence. Il y note l’afflux récent de rapports de bugs dont tout ou partie du texte est généré par un LLM, le « bug » en question étant soit complètement halluciné, soit déformé. C’est une tendance qui se poursuit dans la profession médicale, avec Zahir Kanjee, MD, et ses collègues dans une lettre de recherche de 2023 à JAMA notant que GPT-4 a réussi à donner les bons diagnostics pour les cas fournis dans 64 %, mais seulement 39 % du temps comme principaux diagnostics.
Bien que ce ne soit pas nécessairement terrible, cette précision chute lorsqu’on examine des cas pédiatriques, comme l’ont découvert Joseph Barile, BA et ses collègues dans une lettre de recherche de 2024 dans JAMA Pédiatrie. Ils ont noté que le chatbot ChatGPT avec GPT-4 comme modèle avait un taux d’erreur de diagnostic de 83 % (sur 100 cas). Parmi les diagnostics rejetés, 72 % étaient incorrects et 11 % étaient cliniquement liés mais trop vagues pour être considérés comme un diagnostic correct. Et puis il y a l’incapacité de l’« IA » médicale à s’adapter à quelque chose d’aussi fondamental que de nouveaux patients sans un recyclage approfondi.
Tout cela démontre à la fois le manque d’utilisation des LLM pour les professionnels, mais aussi le risque bien réel lorsque des personnes moins familiarisées avec le domaine en question demandent « l’avis » de ChatGPT.
Les panneaux indiquent « non »
Bien qu’un LLM soit sans doute plus précis que de secouer le bon vieux Magic 8 Ball, un peu comme avec ce dernier, la réponse d’un LLM dépend en grande partie de ce que vous y mettez. En raison de l’annotation, du peaufinage et de l’ajustement incessants non seulement des données du modèle, mais aussi des frontaux et des gestionnaires supplémentaires pour les requêtes qu’un LLM ne peut tout simplement pas gérer, les LLM donnent l’impression de devenir meilleurs et – oserais-je dire – plus intelligents.
Malheureusement pour ceux qui souhaitent voir l’intelligence artificielle sous quelque forme que ce soit devenir une réalité au cours de leur vie, les LLM ne le sont pas. En tant que produit d’un immense travail humain, ils sont bien loin des modèles linguistiques plus basiques qui existent encore aujourd’hui, par exemple sur nos smartphones, où ils apprennent uniquement notre propre vocabulaire et tentent de prédire quels mots ajouter ensuite à la saisie semi-automatique. , ainsi que cette fonctionnalité de correction automatique toujours appréciée. Passer de nLes modèles de langage -gram vers les RNN ont permis des modèles plus grands avec une capacité prédictive accrue, mais le simple fait de faire évoluer les choses n’équivaut pas à l’intelligence.
Pour une personne cynique, l’ensemble de la « bulle de l’IA » est susceptible de ressembler à une autre mode alors que les investisseurs tentent de lancer autant de produits avec la nouvelle nouveauté dedans ou dessus, un peu comme la bulle Internet, la bulle NFT/crypto et tellement avant. Il existe également d’énormes problèmes avec les données utilisées pour ces LLM, car les auteurs humains voient leur travail protégé par le droit d’auteur.
À mesure que les poursuites intentées par ces auteurs progressent devant les tribunaux et que de plus en plus d’études et de procès révèlent qu’il n’y a en effet aucune intelligence derrière les LLM autres que le genre humain, nous ne verrons pas les RNN et les LLM disparaître, mais ils trouveront des niches où leurs points forts. travaillez, car même l’intellect humain a parfois besoin d’un copain robot irréfléchi qui ne perd jamais sa concentration et ne passe jamais une mauvaise journée. Ne vous attendez pas à ce qu’ils fassent notre travail à notre place de si tôt.









{kind=link}