







































Le potentiel de l’intelligence artificielle (IA) et de l’apprentissage automatique (ML) semble presque illimité dans sa capacité à dériver et à générer de nouvelles sources de valeur client, produit, service, opérationnelle, environnementale et sociétale. Si votre organisation doit être compétitive dans l’économie du futur, l’IA doit être au cœur de vos opérations commerciales.

Une étude de Kearney intitulée « L’impact de l’analytique en 2023 » met en évidence la rentabilité et l’impact commercial inexploités pour les organisations à la recherche d’une justification pour accélérer leurs investissements en science des données (IA/ML) et en gestion des données :
- Les explorateurs pourraient améliorer leur rentabilité de 20% s’ils étaient aussi efficaces que les leaders
- Les suiveurs pourraient améliorer la rentabilité de 55% s’ils étaient aussi efficaces que les leaders
- Les retardataires pourraient améliorer leur rentabilité de 81% s’ils étaient aussi efficaces que les leaders
Les impacts commerciaux, opérationnels et sociétaux pourraient être stupéfiants, à l’exception d’un défi organisationnel important : les données. Personne de moins que le parrain de l’IA, Andrew Ng, a noté l’obstacle des données et de la gestion des données à l’autonomisation des organisations et de la société pour réaliser le potentiel de l’IA et du ML :
« Le modèle et le code de nombreuses applications sont fondamentalement un problème résolu. Maintenant que les modèles ont avancé jusqu’à un certain point, nous devons également faire fonctionner les données. — Andrew Ng
Les données sont au cœur de la formation des modèles d’IA et de ML. Et des données fiables de haute qualité orchestrées par des pipelines hautement efficaces et évolutifs signifient que l’IA peut permettre ces résultats commerciaux et opérationnels convaincants. Tout comme un cœur en bonne santé a besoin d’oxygène et d’un flux sanguin fiable, un flux constant de données nettoyées, précises, enrichies et fiables est également important pour les moteurs AI / ML.
Par exemple, un DSI dispose d’une équipe de 500 ingénieurs de données gérant plus de 15 000 tâches d’extraction, de transformation et de chargement (ETL) qui sont responsables de l’acquisition, du déplacement, de l’agrégation, de la normalisation et de l’alignement des données sur des centaines de référentiels de données à usage spécial (données marchés, entrepôts de données, lacs de données et data lakehouses). Ils effectuent ces tâches dans les systèmes opérationnels et orientés client de l’organisation dans le cadre d’accords de niveau de service (SLA) ridiculement stricts pour prendre en charge leur nombre croissant de consommateurs de données diversifiés. Il semble que Rube Goldberg soit certainement devenu un architecte de données (Figure 1).
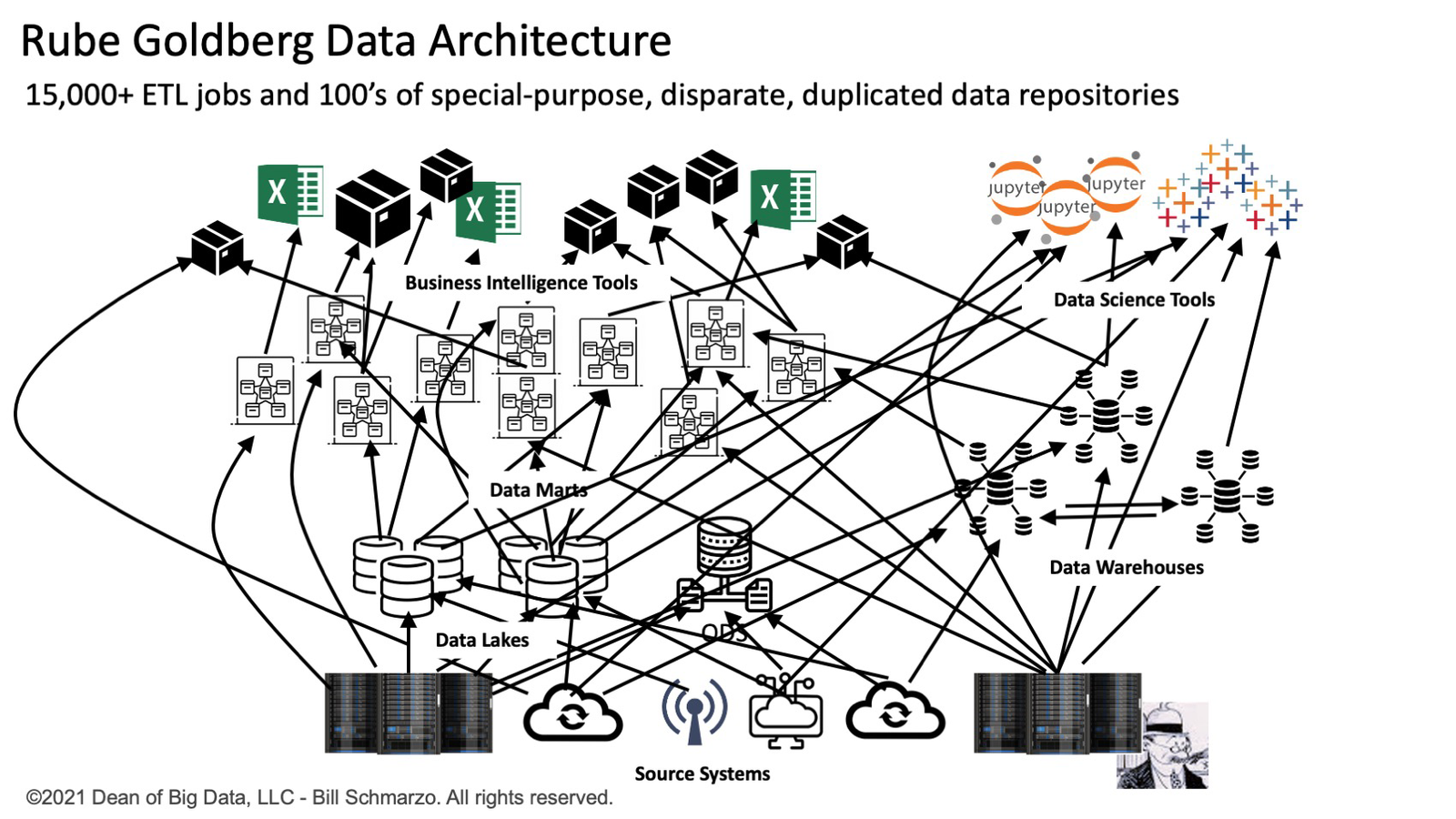
La réduction des structures d’architecture spaghetti débilitantes des programmes ETL statiques ponctuels à usage spécial pour déplacer, nettoyer, aligner et transformer les données inhibe considérablement le « temps d’obtention des informations » nécessaire aux organisations pour exploiter pleinement les caractéristiques économiques uniques des données, la « ressource la plus précieuse du monde » selon L’économiste.
Émergence de pipelines de données intelligents
L’objectif d’un pipeline de données est d’automatiser et de mettre à l’échelle les tâches d’acquisition, de transformation, de déplacement et d’intégration de données courantes et répétitives. Une stratégie de pipeline de données correctement conçue peut accélérer et automatiser le traitement associé à la collecte, au nettoyage, à la transformation, à l’enrichissement et au déplacement des données vers les systèmes et applications en aval. Alors que le volume, la variété et la vitesse des données continuent d’augmenter, le besoin de pipelines de données pouvant évoluer de manière linéaire dans les environnements cloud et cloud hybride devient de plus en plus critique pour les opérations d’une entreprise.
Un pipeline de données fait référence à un ensemble d’activités de traitement de données qui intègre à la fois une logique opérationnelle et métier pour effectuer un approvisionnement, une transformation et un chargement avancés des données. Un pipeline de données peut s’exécuter sur une base planifiée, en temps réel (streaming) ou être déclenché par une règle ou un ensemble de conditions prédéterminé.
De plus, la logique et les algorithmes peuvent être intégrés à un pipeline de données pour créer un pipeline de données « intelligent ». Les pipelines intelligents sont des actifs économiques réutilisables et extensibles qui peuvent être spécialisés pour les systèmes sources et effectuer les transformations de données nécessaires pour prendre en charge les données uniques et les exigences analytiques du système ou de l’application cible.
À mesure que l’apprentissage automatique et l’AutoML se généralisent, les pipelines de données deviendront de plus en plus intelligents. Les pipelines de données peuvent déplacer des données entre des modules avancés d’enrichissement et de transformation de données, où les algorithmes de réseau neuronal et d’apprentissage automatique peuvent créer des transformations et des enrichissements de données plus avancés. Cela comprend la segmentation, l’analyse de régression, le regroupement et la création d’indices avancés et de scores de propension.
Enfin, on pourrait intégrer l’IA dans les pipelines de données de manière à ce qu’ils puissent apprendre et s’adapter en permanence en fonction des systèmes sources, des transformations et enrichissements de données requis, et de l’évolution des exigences commerciales et opérationnelles des systèmes et applications cibles.
Par exemple : un pipeline de données intelligent dans le domaine des soins de santé pourrait analyser le regroupement des codes des groupes liés au diagnostic des soins de santé (DRG) pour garantir la cohérence et l’exhaustivité des soumissions DRG et détecter la fraude lorsque les données DRG sont déplacées par le pipeline de données à partir de la source système aux systèmes analytiques.
Réaliser la valeur commerciale
Les directeurs des données et les directeurs de l’analyse des données sont mis au défi de libérer la valeur commerciale de leurs données, d’appliquer les données à l’entreprise pour générer un impact financier quantifiable.
La capacité à fournir des données fiables et de haute qualité au bon consommateur de données au bon moment afin de faciliter des décisions plus opportunes et plus précises sera un différenciateur clé pour les entreprises riches en données d’aujourd’hui. Un système Rube Goldberg de scripts ELT et de référentiels disparates et spéciaux centrés sur l’analyse entrave la capacité d’une organisation à atteindre cet objectif.
En savoir plus sur les pipelines de données intelligents dans Pipelines de données d’entreprise modernes (eBook) de Dell Technologies ici.
Ce contenu a été produit par Dell Technologies. Il n’a pas été écrit par l’équipe éditoriale du MIT Technology Review.









{kind=link}