







































Vous connaissez probablement cron, un programme qui vous permet de planifier des programmes à exécuter à différents moments. Nous avons également parlé de incron, ce qui est très similaire mais au lieu du temps, il réagit aux changements dans le système de fichiers. Si vous avez toujours voulu écrire un programme qui, par exemple, détecte une modification dans un fichier et le télécharge automatiquement vers un programmeur, le sauvegarde, l’envoie par courrier électronique quelque part, ou quoi que ce soit d’autre, alors incron pourrait être pour vous. Bien que nous en ayons déjà parlé, incron a des particularités qui rendent très difficile le débogage des problèmes, donc j’ai pensé partager quelques-unes des astuces que j’utilise lorsque je travaille avec incron.
J’y pensais parce que je voulais mettre en place un système simple où j’ai un seul répertoire de documents sous contrôle git. La modification d’un fichier de démarque dans ce dossier générerait des documents Word et des équivalents PDF. À l’inverse, la modification d’un document Word produirait une version démarquée.
C’est facile à faire avec pandoc – il parle de nombreux formats différents. L’astuce consiste à l’exécuter uniquement sur les fichiers modifiés et dès qu’ils changent. La tâche n’est pas si difficile, mais elle prend un peu de temps à déboguer car elle n’est pas triviale.
Revue Incron
La configuration d’incron peut être un peu pénible. Je vais supposer que vous avez un moyen de l’installer en utilisant un gestionnaire de paquets comme apt et que votre système utilise systemd pour démarrer et arrêter le service.
Mais il y a plus que ça. Vous devrez être nommé dans le /etc/incron.allow fichier (et non nommé dans /etc/incron.deny). Une fois que vous êtes configuré, il est assez facile à utiliser. Jusqu’à ce que ce ne soit pas le cas.
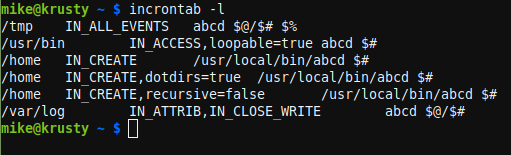
Chaque utilisateur dispose d’un incrontab. Utilisation: man 5 incrontab pour en savoir plus. Pour le modifier, utilisez cette commande:
incrontab -e
Chaque ligne comporte trois champs et vous devez utiliser un seul onglet entre chaque champ. Le premier champ est le répertoire ou le fichier à surveiller, le second champ contient des entrées séparées par des virgules pour indiquer à incron le type de modifications que vous recherchez et quelques autres options. Le dernier champ est la commande à exécuter.
Vous pouvez utiliser certains caractères spéciaux dans la ligne de commande. $@ vous donne le nom du répertoire, par exemple. le $# macro est le nom du fichier tandis que $% vous donne le type d’événement sous forme de chaîne ($& est un code numérique pour le même). Si vous avez besoin d’un vrai signe dollar, doublez-le.
Les événements sont des choses comme IN_CREATE, IN_DELETE, IN_MODIFY, et plein d’autres. Vous pouvez utiliser n’importe quel nombre d’entre eux ensemble, utilisez simplement des virgules entre eux. J’aurai plus à dire à ce sujet plus tard. Il existe également des options comme IN_DONT_FOLLOW ce qui arrête le déréférencement des liens symboliques. Vous pouvez également définir recursive=false pour arrêter de surveiller les sous-répertoires et loopable=true qui est censé arrêter un problème commun mais pas toujours.
Vous verrez une documentation sur Internet qui est parfois obsolète. Le développement actuel est sur GitHub, mais le développeur principal s’est arrêté en 2012 et il y avait un intervalle de deux ans avant que quelqu’un le ramasse pour des corrections de bogues. Parfois, il est utile de lire le code source de la version, vous devez comprendre exactement ce qui se passe.
Qu’est ce qui ne va pas avec ça?
Le service incron souffre d’une crise d’identité. À la fois par sa fonction et son nom, il doit être similaire à cron, non? Superficiellement, c’est vrai, mais les détails sont un peu différents. D’une part, les anciennes versions d’incron n’autorisent pas les commentaires dans le tableau. Vous pensez peut-être que vous avez commenté quelque chose, mais ce n’est pas vraiment le cas. En plus de cela, il est très difficile d’obtenir la sortie de vos commandes ou même un statut décent. Pas impossible, cependant, juste difficile. Les versions récentes autorisent les commentaires, mais cela a pris du temps, et votre version peut ou non être à jour.
L’autre chose qui pose souvent problème est que toute action que vous entreprenez dans votre programme et qui déclenche une modification du système de fichiers peut vous mettre dans une boucle sans fin. On pourrait penser qu’Incron comprendrait cela et ferait quelque chose. Au lieu de cela, votre ligne unique dans votre incrontab privé peut planter tout le démon.
Pour compliquer davantage les choses, de nombreux programmes font des choses auxquelles vous ne vous attendez pas et qui interrompent certains événements. Vous pourriez penser, par exemple, que si vous voulez savoir quand un fichier change, vous devez surveiller IN_MODIFY. Logique. Mais la plupart des éditeurs ne fonctionnent pas de cette façon. Si vous modifiez le fichier, cela fonctionnera parfois sur une copie du fichier dans / tmp et alors l’opération de sauvegarde est vraiment un déplacement. Parfois, les programmes avec des fonctions similaires auront des flux d’événements différents. Par exemple, scp et rsync gérer les fichiers différemment et attraper quand un nouveau fichier apparaît nécessitera une manipulation différente selon le programme qui l’a mis là.
Le premier conseil: connectez-vous pendant que vous travaillez sur les commandes
Cela conduit donc au premier conseil. Écrivez une règle temporaire en utilisant le mot-clé IN_ALL_EVENTS et utilisez un petit script shell pour simplement consigner ce qui se passe lorsque vous pensez qu’il arrivera au fichier. Vous pourriez trouver les résultats surprenants et il est préférable de comprendre le flux d’événements pour votre cas d’utilisation avant de commencer à écrire de vrais scripts.
Supposons que vous ayez un script appelé echoarg.sh:
#!/bin/bash fn="$1" shift echo "$@" >>"$fn"
Juste un script rapide et sale, mais vous pouvez l’utiliser avec incron:
/home/user/tmp/itest IN_ALL_EVENTS /bin/bash echoarg.sh /home/user/tmp/echoarg.log $% - $@/$#
Les noms de fichiers devraient bien sûr avoir des guillemets, mais puisque nous ne faisons que les imprimer, cela n’a pas d’importance ici. Une chose à noter: certaines installations ne permettront pas à incron d’écrire dans des endroits comme / tmp ou même de surveiller des fichiers là-bas. Vous feriez mieux de vous en tenir à un répertoire que vous savez posséder (dans ce cas / home / user / tmp). Voici le résultat de la course touch foo dans le ~/tmp/itest annuaire:
IN_ATTRIB - /home/user/tmp/itest/foo IN_CREATE - /home/user/tmp/itest/foo IN_OPEN - /home/user/tmp/itest/foo IN_CLOSE_WRITE - /home/user/tmp/itest/foo
Plus de choses à craindre
Chaque distribution regroupe les choses un peu différemment, vous devrez peut-être lire une documentation. Par exemple, sur les systèmes basés sur Debian, le peu de données consignées par incron est écrit dans le journal système. Mais sur certaines autres distributions courantes, il réutilise le fichier journal cron.
Le programme est également très pointilleux sur les espaces et les tabulations. Ainsi, un espace parasite entre les deuxième et troisième champs va gâcher les choses. Ainsi sera un onglet après le nom du programme, le shell prendra l’onglet et le jeton suivant comme faisant partie du nom du programme.
En parlant de shell, incron est très particulier pour trouver des shells et définir des environnements. Votre version peut varier, mais la chose la plus sûre à faire est de supposer que vous aurez besoin d’un chemin vers tout et d’un shell explicite dans l’incrontab. Si vous avez besoin de choses spéciales dans le PATH ou une autre configuration d’environnement, faites-le dans le script. Même si vous exécutez un binaire, il vaut la peine d’écrire un petit wrapper pour que vous puissiez tout configurer comme vous le souhaitez. À tout le moins, lorsque vous exécutez votre test, videz l’environnement d’exécution dans un fichier journal temporaire afin de ne pas découvrir à la dure que vous manquez beaucoup de votre environnement attendu.
L’utilisation d’une commande comme $ (date) est vouée à l’échec car incron va manger le signe dollar. Si vous vous sentez chanceux, essayez d’utiliser $$ (date).
Le grand événement
Une fois que vous avez compris les événements que vous souhaitez traiter, vous devez écrire votre script et le tester autant que vous le pouvez sans utiliser incron. Dans mon cas, j’ai écrit autopandoc avec l’idée d’ajouter les fonctions PDF plus tard:
#!/bin/bash
if [ -z "$1" ]
then
exit 1
fi
if [ ! -f "$1" ]
then
exit 2
fi
dir=$(dirname "$1")
ffilename=$(basename -- "$1")
ext="${ffilename##*.}"
filename="${ffilename%.*}"
case "$ext" in
doc*) newext="md"
;;
md) newext="docx"
;;
*) exit 3
esac
if [ ! -f "$dir/generated" ]
then
mkdir "$dir/generated"
fi
exec pandoc "$1" -o "$dir/generated/$filename.$newext"
Ceci est simple à exécuter à partir d’une ligne de commande avec de faux arguments de répertoire, de fichier et d’événement et assurez-vous que la logique fait ce que vous voulez. Croyez-moi, ce sera beaucoup plus facile que le débogage pendant les événements incron.
Ma première tentative n’a pas bien fonctionné du tout et il y avait très peu d’explications. En regardant les journaux, je pouvais voir que les événements de fichier se produisaient, mais il n’y avait aucune preuve que mes scripts – aussi simples soient-ils – étaient en cours d’exécution. Il s’avère que l’ajout d’un / bin / bash explicite à la table a tout fonctionné.
Cependant, obtenir incron pour arrêter le redéclenchement si j’écrivais dans le même répertoire s’est avéré difficile. J’ai fini par créer un sous-répertoire qui déclencherait un changement qui ferait ensuite un autre sous-répertoire, déclenchant un autre changement. Finalement, incron mourrait. Pas seulement un fil de travail pour mon utilisateur. Incron mourrait pour tous les utilisateurs. Je suppose que vous pourriez changer systemd pour le relancer, mais ce n’est pas vraiment une solution.
Il existe quelques options pour empêcher incron de réagir plusieurs fois au même fichier, mais créer un nouveau fichier provoque toujours des événements et, honnêtement, si ce n’était pas le cas, ce serait un autre problème si vous essayiez de gérer plusieurs utilisateurs. J’ai fini par faire du punting, mais d’abord, voyons comment vous pouvez jeter un œil à ce qui se passe pendant une course incronale.
C’est Log!
Comme je l’ai mentionné, le fichier journal peut apparaître à plusieurs endroits. KSystemLog est pratique si vous utilisez KDE car il peut filtrer et vous montrer les événements au fur et à mesure qu’ils se produisent. Vous pouvez également utiliser tail -f, bien sûr, mais vous pourriez avoir besoin d’un grep pour réduire le bruit.
Si vous utilisez systemd, vous pouvez essayer quelque chose comme ceci:
journalctl -f -u incron.service
Cela agit comme un tail -f pour le fichier journal incron. Regarder incron déclencher à plusieurs reprises des événements sur / my_dir / subdir / subdir / subdir…. vous en dira beaucoup sur ce qui se passe dans votre script.
Autres conseils: exécutez le démon vous-même, utilisez strace et optimisez vos montres
Vous pouvez arrêter le démon incron en utilisant les méthodes de votre choix (par exemple, systemctl stop incron) puis exécutez incrond toi-même avec le -n option. Cela vous montre ce que fait le programme. Assurez-vous de l’exécuter en tant que root.
Une autre chose qui rend possible l’utilisation strace pour exécuter le programme. Cela révélera tous les appels système effectués par le programme, donc si vous vous demandez quels fichiers il ouvre et les résultats de ceux-ci, c’est la façon de le faire:
sudo strace incrond -n
le -n option fait que le programme reste au premier plan. N’oubliez pas de le tuer lorsque vous avez terminé et de redémarrer le service. Bien sûr, si vous êtes sur une machine que vous partagez avec d’autres personnes, c’est probablement une idée assez grossière.
Si vous commencez à utiliser incron, il se peut que vous soyez à court de surveillance du système de fichiers. Si vous le faites, essayez:
sysctl fs.inotify.max_user_watches
Vous pouvez modifier temporairement le nombre autorisé en utilisant
sysctl -w fs.inotify.max_user_watches=1000000
Rendez-le permanent en éditant /etc/sysctl.conf ou ajoutez un fichier dans /etc/sysctl.d.
Est-ce que ça marche?
Une fois que vous faites fonctionner les choses, cela fonctionne bien. Pour la production, cependant, cela m’inquiète qu’un script errant puisse planter l’ensemble du service. Il existe des alternatives. Si cela ne vous dérange pas, il y a des unités de chemin. Il existe plusieurs alternatives possibles sur GitHub, bien qu’aucune ne semble récemment maintenue.
Comme la plupart des outils Linux, c’est parfois le bon choix, et parfois vous voudrez utiliser autre chose. Mais il est toujours utile de comprendre tous les outils que vous pouvez avoir dans votre boîte.









{kind=link}